
The alignment repair game setting.
Our cultural knowledge evolution work first applied to alignment evolution before being extended to ontology evolution. Experiments have revealed that, by playing simple interaction games, agents can effectively repair random networks of ontologies or even create new alignments and ontologies.
Alignments between ontologies may be established through agents holding such ontologies attempting at communicating and taking appropriate actions when communication fails. We have tested this approach on alignment repair, i.e. the improvement of incorrect alignments. For that purpose, we performed a series of experiments in which agents react to mistakes in alignments. Agents may use ontology alignments to communicate when they represent knowledge with different ontologies: alignments help reclassifying objects from one ontology to the other. Such alignments may be provided by dedicated algorithms [Da Silva 2020a], but their accuracy is far from satisfying. Yet agents have to proceed. Agents only know about their ontologies and alignments with others and they act in a fully decentralised way. They can take advantage of their experience in order to evolve alignments: upon communication failure, they will adapt the alignments to avoid reproducing the same mistake.
Such repair experiments have been performed [Euzenat 2014c] and revealed that, by playing simple interaction games, agents can effectively repair random networks of ontologies.
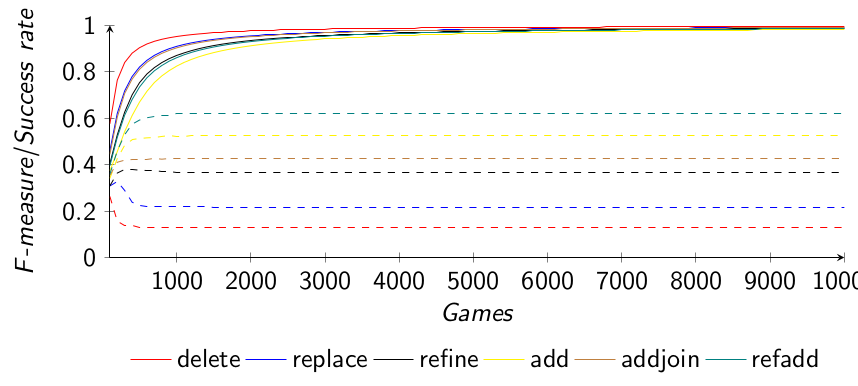
We repeated these experiments and, using new measures, showed that the quality of previous results was underestimated. We introduced new adaptation operators (refine, addjoin and refadd) that improve those previously considered (delete, replace and add). We also allowed agents to go beyond the initial operators in two ways [Euzenat 2017a]: they can generate new correspondences when they discard incorrect ones, and they can provide less precise answers. The combination of these modalities satisfy the following properties:

The results above show 100% precision for all adaptation operators, i.e. all the correspondences in the alignments were correct, but were still missing some correspondences, and did not achieve 100% recall. We had conjectured that this was due to a phenomenon called reverse shadowing [Euzenat 2017a], avoiding to find specific correspondences.
We introduced a new adaptation modality, strengthening, to test this hypothesis. The strengthening modality replaces a successful correspondence by one of its subsumed correspondences covering the current instance. This modality is different from those developed so far, because it leads agents to adapt their alignment when the game played has been a success (previously, it was always when a failure occurred). We defined three alternative definitions of this modality depending on if the agent chooses the most general, most specific or a random such correspondence.
We experimentally showed that it was not interferring with the other modalities as soon as the add operator was used. This means that all properties of the previous adaptation operators are preserved. Moreover, as expected, recall was greatly increased, to the point that some operators achieve 99% F-measure. However, the agents still do not reach 100% recall.
The work on expansion suggests that, with the expansion modality, agents could develop alignments from scratch. We explored the use of expanding repair operators for that purpose. When starting from empty alignments, agents fail to create them as they have nothing to repair. Hence, we introduced the capability for agents to risk adding new correspondences when no existing one is useful [Euzenat 2017b]. We compared and discussed the results provided by this modality and showed that, due to this generative capability, agents reach better results than without it in terms of the accuracy of their alignments. When starting with empty alignments, alignments reach the same quality level as when starting with random alignments, thus providing a reliable way for agents to build alignment from scratch through communication. The evolution curves of both approaches (random and empty alignments), passed a starting phase in which figures correspond to this initial conditions, superimpose nearly exactly. This comfort a posteriori the experiments with random initialisation.
To adopt a population standpoint on experimental cultural evolution, we introduced the concept of population within the experiments. So far, a population is characterised as a set of agents sharing the same ontology. Such agents play the same alignment repair games as before with agents of other populations.

The notion of population enables to experiment with different transmission mechanisms: social transmission, in which culture spreads among agents of the same population, and wide transmission, in which it spreads across populations. We implemented explicit social transmission through a synchronisation procedure: at a given interval, agents of the same population exchange their knowledge, i.e. alignments. Each population builds a consensus and agents integrate the consensus into their local knowledge. The consensus consisting of merging alignments, may be obtained by vote or by preserving the most specific or most general correspondences.
Initially it was hypothesised that such knowledge transmission can help agent achieve faster convergence, but the results suggest otherwise. Agents regularly replace their (repaired) local alignment by the (conservative) population consensus which slows down the convergence significantly.
We have proposed three different ways in which agents can be critical towards the population consensus: They will adopt the consensus either based on a probability law, based on the distance between the consensus and their local alignment or based on the memory that the agent have of discarded correspondences. We tested all three approaches and found that agents can achieve faster convergence and produce alignments of comparable quality.
After alignment repair, we consider how agents may learn and evolve their ontologies.
So far our experiments in cultural knowledge evolution dealt with adapting alignments. However, agent knowledge is primarily represented in their ontologies which may also be adapted. In order to study ontology evolution, we designed a two-stage experiment in which:
In this scenario, fundamental questions arise: Do agents achieve successful interaction (increasingly consensual decisions)? Can this process improve knowledge correctness? Do all agents end up with the same ontology? We showed that agents indeed reduce interaction failure, most of the time they improve the accuracy of their knowledge about the environment, and they do not necessarily opt for the same ontology [Bourahla 2021a].
Knowledge transmission occurring between agents of the same generation, as described above, is considered as horizontal transmission. Other work has shown that variation generated through vertical, or inter-generation, transmission allows agents to exceed that level [Acerbi 2006a]. Such results have been obtained under the drastic selection of (less than 20%) agents allowed to transmit their knowledge or introducing artificial noise during transmission.
In order to study the impact of such measures on the quality of transmitted knowledge, we combined the settings of these two previous work and relaxed these assumptions (no strong selection of teachers, no fully correct seed, no introduction of artificial noise). Under this setting, we confirmed that vertical transmission improves on horizontal transmission even without drastic selection and oriented learning. We also showed that horizontal transmission is able to compensate for the lack of parent selection if it is maintained for long enough [Bourahla 2022a].
The work on cultural knowledge evolution reported above concentrated on agents performing a single task. This is not a natural condition, thus we are developing agents able to carry out several tasks and to adapt their knowledge with the same protocol. We introduced multi-tasking agents that interact over a limited set of tasks. By varying the number of tasks assigned to each agent and the number of common properties across these tasks, we found that agents transfer knowledge from one task to another [Kalaitzakis 2023b]. But, counter-intuitively, our experiments demonstrate that multi-task agents are not necessarily less accurate than specialised one.
We limited agent memory size in order to avoid multi-tasking agents to learn all tasks in the long term. Agents with limited memory specialize on a subset of tasks, whose number depends on available memory. However, it seems that maximising task accuracy and achieving consensus are mutually exclusive. Agents can either specialise in detriment of their interoperability, or learn to agree but fail to specialise [Kalaitzakis 2023a].
We tried to test the intuition that randomly forgetting parasitic knowledge in pluripotent agents may help them develop more correct knowledge. While temporarily detrimental to their knowledge correctness, forgetting randomly selected knowledge brings long-term benefits when agents are assigned a single task. However, when agents specialising in different tasks interact, one task will gradually monopolise the collectively available resources, causing the entire society to specialise in the same task [Kalaitzakis 2024a].
Cultural values are cognitive representations of general objectives, such as independence or mastery, that people use to distinguish whether something is `good' or `bad'. More specifically, people may use their values to evaluate alternatives and pick the most compatible one. We consider values as grounding agent behaviour in cultural knowledge evolution, and more specifically in the way they evolve their ontologies. We used the cultural values of independence, novelty, authority and mastery to influence the choice of which agent adapts in a population of agents sharing the same values. From a weighted aggregation of how much agents adhere to these values, they determine which one adapts its knowledge when two agents disagree, e.g. novelty will give more change to rare knowledge, though mastery will promote knowledge that has proved efficient. Results [Luntraru 2023a] show that agents do not improve the accuracy of their knowledge without using the mastery value (akin the success biais in social learning [Bourahla 2023a]). Under certain conditions, independence causes the agents to converge to successful interactions faster, and novelty increases knowledge diversity, but both effects come with a large reduction in accuracy. We did not find any significant effects of authority.
In cultural knowledge evolution simulations, agent knowledge might be confined to specific areas because the tasks that they perform do not require them to explore more. We considered how agents may be provided with the intrinsic motivation to explore and how this affects their knowledge. Three different kinds of motivation were investigated: curiosity (the will to explore the unknown), creativity (the will to act differently) and non-exploration (the will to not explore new things). Moreover, intrinsic motivation was modelled directly or learned through reinforcement learning. Finally, agents either explored on their own or picked specific interaction partner(s). We have shown that such settings may have a significant effect on the agent knowledge [Siebers 2023a]. Contrary to the expectations and other studies, this did not lead to an increase in knowledge completeness. Out of all intrinsic motivations, curiosity had the highest accuracy and completeness. Models with reinforcement learning performed similarly as direct models. As expected, intrinsic motivation led to faster convergence of the agents’ knowledge, especially with social agents. Heterogeneously motivated agents had a higher accuracy and completeness than homogeneously motivated agents only in specific cases.
Previous work on computational cultural evolution observes the effect of static adaptation operators (see Evolving ontologies). Our recent work uses reinforcement learning to learn to adapt agent's decisions. But because decisions are directly selected, learned policies depend on the environment. Hence, they do not perform well in different environments. We aim at learning environment-independent policies to play a specific game type. For that purpose, we designed agents that use reinforcement learning to learn policies combining different knowledge adaptation operators, instead of learning how to make decisions. Decisions are thus guided by a symbolic knowledge base updated with the learned policy, but rewards go to the policy operators. Thus, these adaptation policies depend, through the operators, on the knowledge structure rather than the specific content of the environment. Results show that these policies allow agents to efficiently complete the games and remain effective across different environments.
Assessing knowledge diversity may be useful for many purposes. In particular, it is necessary to measure diversity in order to understand how it arises or is preserved. It is also necessary to control it in order to measure its effects. We have considered measuring knowledge diversity using two components: (a) a diversity measure taking advantage of (b) a knowledge difference measure [Bourahla 2021a]. We have proposed general principles for such components and compared various candidates [Bourahla 2022c]. The most satisfycing solutions are entropy-based measures [Leinster 2021a]. We designed and implemented algorithms using these measures to generate populations of agents with controlled levels of knowledge diversity.
Opinion dynamics models how social organisation and interactions determine opinions. Belief propagation also studies how logical beliefs propagate within a network. However, it is expected that opinions and beliefs do not evolve independently. Yet, there is hardly any attempts to connect them.
We put forth a model in which opinions and beliefs, besides these two social operations, are also connected by two ‘cognitive’ operations: opinion formation from beliefs and belief alignment with opinions. They aim at reducing the cognitive dissonance between beliefs and opinions adopted from the social propagation. The four resulting operations are very flexible in their implementations. We used the DeGroot opinion dynamic model and belief revision game operations for the social operations. We based the cognitive operations on cultural values held by the agents. The value-based mechanism is balanced with the inertia, or propensity to avoid change, of agents. They allow for modelling various types of agents (favouring opinions, favouring beliefs, eager to change, resisting to change, etc.).
We showed that the outcome of the propagation processes depends on graph topology, initial opinions and beliefs as in classical opinion dynamics and belief revision games [kataoka2026a]. In addition, we show that both opinions influence beliefs and beliefs influence opinions and that outlier beliefs do not spread more but have an influence on the final beliefs.
Echo chambers, the state in which agents are split into groups sharing the same opinion, is a well-known phenomenon in social networks. Opinion dynamics models have been proposed to explain how the phenomenon occurs through agents revising their opinions. However, social network users also exchange beliefs supporting their opinions. This has not been taken into account. We have extended an existing opinion dynamics model by allowing agents to exchange and update both beliefs and opinions. The process of updating beliefs is described based on the classical belief revision theory. Beliefs and opinions can influence each other guided by values that agents share. We compared opinion propagation with respect to belief influence. Simulation results show that connecting beliefs and opinions increases the number of echo chambers [kataoka2025a].
The Alignment Repair Game (ARG) has been proposed for agents to simultaneously communicate and repair their alignments through adaptation operators when communication failures occur [Euzenat 2017a]. ARG was evaluated experimentally and the experiments showed that agents converge towards successful communication and improve their alignments. However, the logical properties of such operators, i.e. whether they are formally correct, complete or redundant, could not be established by experiments. We introduced Dynamic Epistemic Ontology Logic (DEOL) to answer these questions. It allows us [van den Berg 2020a, 2021a] (1) to express the ontologies and alignments used, (2) to model the ARG adaptation operators through announcements and conservative upgrades and (3) to formally establish the correctness, partial redundancy and incompleteness of the adaptation operators in ARG.
These results raise interesting issues about how closely a multi-agent process should be modelled logically (indeed, it is possible to make agents closer to the logic or try to have a logical model closer to the agents). They also open the perspective to model cultural (knowledge) evolution as a whole with dynamic epistemic logics [van den Berg 2021b].
In the DEOL modelling, agents are aware of the vocabulary that the other agents may use (we call this Public signature awareness). However, assuming that agents are fully aware of each other's signatures prevents them from adapting their vocabularies to newly gained information, from the environment or learned through agent communication. Therefore this is not realistic for open multi-agent systems. We have proposed a novel way to model awareness with partial valuations functions and weakly reflexive relations [van den Berg 2020b, 2023a]. Partial Dynamic Epistemic Logic allows agents to use their own vocabularies to reason and talk about the world. We added dynamic modalities for raising public and private awareness in which a distinction is made between becoming aware of a proposition and learning its truth value. As a result, the semantics introduced can be used to model agent interaction without the public signature awareness assumption. We also investigated associated forgetting operators [van den Berg 2023a].
When representing an agent's beliefs with a belief base, a distinction can be made between beliefs explicitly contained in the belief base and those that can be derived from it. This allows to consider agents with imperfect (unsound or uncomplete) reasoning abilities as often in cultural evolution.
The logic of doxastic attitudes models this distinction in epistemic logic through modal operators for explicit and implicit beliefs, and a semantics based on the notion of belief bases. We extended this framework to allow agents to hold explicit beliefs about other agents' implicit beliefs and suggested an alternative semantics that can model agents with imperfect reasoning. We proved that the new semantics, when restricted to agents that can derive from a set of formulas all that it logically entails, is indeed equivalent to the original one.
Cultural evolution may be studied at a `macro' level, inspired from population dynamics, or at a `micro' level, inspired from genetics. The replicator-interactor model generalises the genotype-phenotype distinction of genetic evolution. We considered how it can be applied to cultural knowledge evolution experiments [Euzenat 2019a]. More specifically, we consider knowledge as the replicator and the behaviour it induces as the interactor. We showed that this requires to address problems concerning transmission. We discussed the introduction of horizontal transmission within the replicator-interactor model and/or differential reproduction within cultural evolution experiments.

We defined a protocol to experiment with human learners various modalities of knowledge transmission based on the Class? game. In particular, we want to test the effect of the medium on knowledge acquisition and evolution. In other words, is the hybrid mode of teaching closer to the written modality of knowledge transmission or to the face-to-face classroom modality? This protocol involves groups of pupils learning how to play the game and transmitting it to the next group. Transmission modalities varied in terms of face-to-face physical presence, online or written transmission. A series of tests have been designed in order to determine which playing strategies are acquired by pupils after transmission and after playing.
| Publications on cultural knowledge evolution |